- Mar 2, 2021
- 4 min
Managing hundreds of code branches with Jenkins
-
 Maxime MichelSite Reliability Engineer, Magnolia
Maxime MichelSite Reliability Engineer, Magnolia

Magnolia in action
Take 12 minutes and a coffee break to discover how Magnolia can elevate your digital experience.
At Magnolia, one of the biggest challenges in our CI is the total number of jobs we are working with. We maintain around a hundred modules for which we have multiple parallel active releases. In this blog, we'll discuss the slim setup that allows us to maintain and build those hundreds of branches.
Luckily for us, most of our modules follow the same pattern: a Maven build on steroids. The crux of the matter is to build, test and deploy artifacts to Nexus, while being able to add custom steps - all using Jenkins. Finding an effective and flexible solution took us some time. With that said, let me explain how we did it using Bitbucket, pipeline templates, and the Pipeline Maven Integration plug-in.
Bitbucket
We use Bitbucket to manage all our projects. Our Maven modules and reactors reside in a project folder under https://git.magnolia-cms.com/projects. Each of our modules can have multiple actively maintained branches. Some also have open pull requests.
While our Bitbucket instance is fully aware of all developer activity, our Jenkins instance doesn't need to be aware of everything that gets pushed. Inactive branches are of no interest to the Jenkins instance, and it doesn’t need to know when a developer pushes work to a test branch to share it with a colleague either. Giving all Git hashes the same importance would increase the processing cost and slow our developers down because irrelevant builds would congest the queue and delay the relevant builds.
Our Jenkins instance only looks for branches named master or release/* that contain a Jenkinsfile. This is our Bitbucket job configuration:
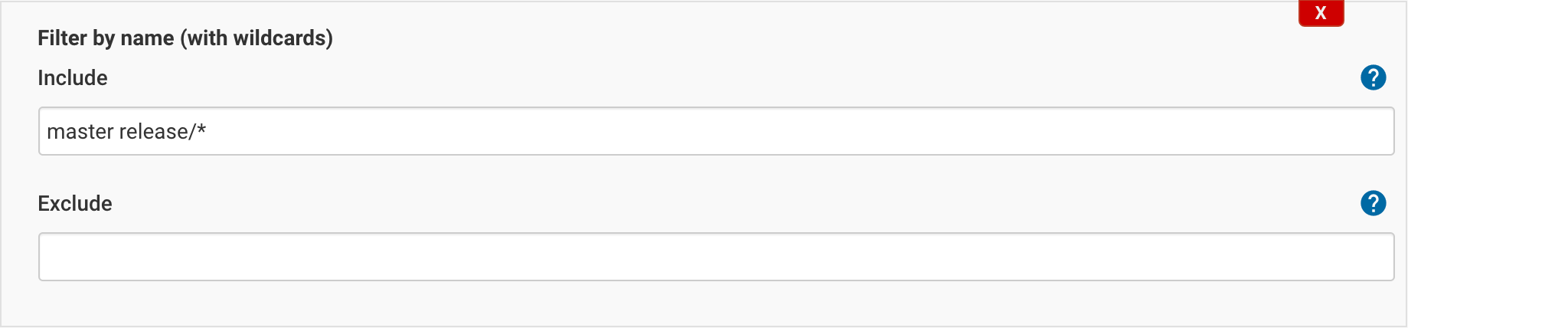
If you plan to implement this setup, you may want to prevent force pushing to those branches, or enforce merging exclusively through pull requests in the Bitbucket permission scheme that applies to your repositories.
Pipeline templates
When Jenkins picks up the Jenkinsfile it is crucial that it doesn’t redefine the build steps. It would be a nightmare if each branch changed properties such as the Maven or Docker version, or the flags for the different stages in which we use Maven. If we ever had to update any of those parameters, it would require half a day of repetitive work for a developer to change every single branch.
Instead, we leverage Jenkins' shared libraries to share snippets, settings, and templates across our builds using one line of code:
1magnoliaDefaultPipeline() This function replaces a pipeline like this:
1pipeline {
2 agent { node { label 'aws' } }
3 stages {
4 stage('Build and deploy') {
5 when {
6 anyOf { branch 'master'; branch 'main'; branch 'release/*' }
7 }
8 steps {
9 script {
10 withMaven() {
11 sh 'mvn deploy'
12 }
13 }
14 }
15 }
16 }
17} magnoliaDefaultPipeline() pulls the job definition vars/magnoliaDefaultPipeline.groovy from our pipeline-templates triggering the following jobs in the branch's build automatically:
Clone our build scripts
Run the Maven build
Test binary compatibility
Check for dependency analysis warnings
Run a JIRA health check
Magnolia in a Can: Containerization with Magnolia
Learn how to deploy Magnolia as a Docker container based on best practices from our professional services team
Pipeline Maven Integration
Another essential piece of the puzzle is the Pipeline Maven Integration plug-in.
The process that I’ve described so far allows us to build many independent modules using a simple setup.
But Magnolia is built from many modules in a specific order: main, UI, community modules, community webapps, enterprise modules, and enterprise webapps. For instance:

This is possible by calling the plug-in almost anywhere where we use Maven in a pipeline:
1withMaven(mavenParameters.get()) {
2 sh "mvn deploy"
3} The plug-in is responsible for scanning which modules a branch depends on. It also knows which modules have already been built on the Jenkins instance. It can therefore trigger any relevant downstream job when a build finishes. This is how we maintain our trigger chain dynamically without any developer involvement.
AWS build scripts
Bash scripts are the only file type we could not centralize using shared libraries. We found a solution by having our pipelines clone them as a first step. You can find more details about this approach in our article on testing bash scripts with Jenkins.
Conclusion
Managing hundreds of branches in Jenkins can be a challenge. We’ve thought of simplifying the problem by grouping modules together, but this approach would have added little value to the product compared to bug fixes and new features. We’ve tried alternative CI solutions, but didn’t find one on the market that was built for a modular setup like ours.
Thanks to published research, PoCs, and libraries, we finally came up with the approach explained in this blog helping us to manage our CI in a way that makes our developers happy. We have very few hiccups with this setup and I hope that this blog allows you to replicate what we’ve done.
We’ve also recently discovered the Modular Pipeline Library, taking the approach even further and intend to experiment with it going forward.








